Copy-paste code 10 lần, sai lần thứ 11 mới phát hiện
18 tháng 4, 2023
Năm đầu tiên đi làm, tôi đo lường thành công bằng một con số: bao nhiêu dòng code gõ ra mỗi ngày. Lúc ấy, tôi sợ mình viết code quá chậm. Sợ bị đánh giá là không năng suất.
Sau hai năm, tôi phát hiện ra cái sợ đó đảo chiều hoàn toàn.
Tôi nhận ra phần lớn thời gian hàng ngày của mình không dùng để suy nghĩ giải pháp cho những bài toán khó. Tôi dành hàng giờ, thậm chí cả ngày, chỉ để lặp lại một công việc duy nhất: sao chép cấu trúc code từ file này sang file khác rồi đổi tên các thực thể dữ liệu.
Hôm nay tôi cần viết tính năng quản lý sinh viên. Tôi tạo ra một loạt file: StudentController, StudentService, StudentRepository, StudentDto, CreateStudentRequest.
Ngày mai, dự án yêu cầu quản lý thêm giảng viên. Tôi lại mở trình soạn thảo, tạo ra các file tương tự: TeacherController, TeacherService, TeacherRepository, TeacherDto, CreateTeacherRequest.
Cấu trúc bên trong các file này giống nhau đến chín mươi phần trăm. Khác biệt duy nhất chỉ là từ khóa “Student” được thay thế bằng từ khóa “Teacher”. Các thuộc tính bên trong được sửa từ thông tin học tập của sinh viên thành thông tin giảng dạy của giảng viên.
Tôi bắt đầu cảm thấy mình giống một cái máy photocopy chạy bằng cơm hơn là một kỹ sư phần mềm. Tôi tự hỏi, nếu quy trình viết code này có tính lặp lại cao và tuân theo những quy tắc cụ thể đến vậy, tại sao máy tính không tự làm thay chúng ta?
Nghiệp chướng từ những tính năng CRUD
Trong ngành phát triển phần mềm, đặc biệt là mảng xây dựng ứng dụng doanh nghiệp hoặc hệ thống SaaS, phần lớn khối lượng công việc xoay quanh khái niệm CRUD: Thêm, Đọc, Sửa và Xóa.
Để hoàn thành một tính năng CRUD cơ bản theo kiến trúc phân lớp tiêu chuẩn, một lập trình viên không chỉ viết vài câu lệnh truy vấn dữ liệu. Chúng ta phải dựng lên một bộ khung đồ sộ với hàng loạt file bổ trợ.
Entity đại diện cho bảng dữ liệu. Data Transfer Object (DTO) để chuyển dữ liệu qua lại giữa các lớp. Request và Response định nghĩa dữ liệu đầu vào đầu ra của API. Lớp Validation để kiểm tra dữ liệu. Cấu hình Swagger để sinh tài liệu. Rồi đến Repository, Service, Controller để tiếp nhận yêu cầu HTTP.
Mỗi file này thường chỉ dài từ vài chục đến hơn một trăm dòng code. Chúng không khó viết. Chúng không đòi hỏi những thuật toán tối ưu phức tạp.
Nhưng chúng chiếm dụng một khoảng thời gian khổng lồ.
Việc viết đi viết lại những đoạn code này không chỉ gây nhàm chán mà còn là nơi ẩn nấp của những lỗi ngớ ngẩn nhất. Một lập trình viên làm việc trong trạng thái mệt mỏi sau khi copy code từ file cũ sang file mới rất dễ quên sửa tên một trường dữ liệu ở tầng mapping hoặc validation. Chương trình vẫn biên dịch được, API vẫn chạy, nhưng dữ liệu lưu vào database bị sai lệch hoặc thiếu thông tin mà không có cảnh báo nào xuất hiện ngay lập tức.
Đó là lúc nghiệp chướng từ sự cẩu thả bắt đầu đòi nợ. Việc tìm ra những lỗi nhỏ này sau đó thường mất nhiều thời gian hơn cả việc viết code ban đầu.
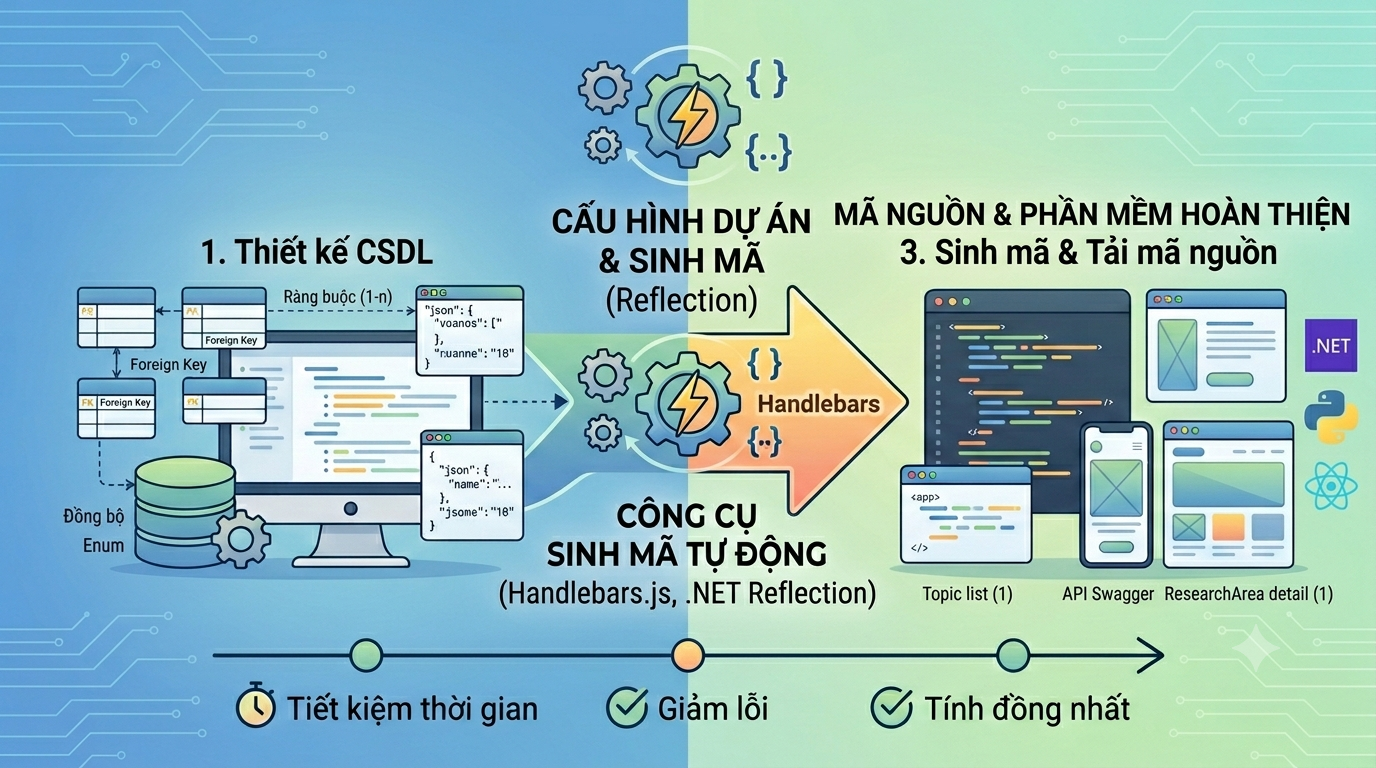
Năm 2023, khi thực hiện luận văn thạc sĩ về chủ đề tự động hóa sinh mã nguồn, tôi đã dành nhiều thời gian để phân tích bài toán này. Tôi nhận thấy đây thực chất là bài toán về năng suất lao động trong công nghiệp phần mềm. Chúng ta đang lãng phí chất xám của các kỹ sư vào những công việc mang tính thủ công và lặp đi lặp lại.
Quy tắc hóa để tự động hóa
Nhìn vào bức tranh tổng thể, ngành công nghiệp phần mềm đã tìm cách giải quyết vấn đề này qua nhiều hướng tiếp cận khác nhau, từ Low-code, No-code cho đến sinh mã nguồn dựa trên template mẫu.
Tôi đặt ra một giả định: nếu toàn bộ kiến trúc phần mềm và cách viết code của chúng ta đã được chuẩn hóa thành các quy tắc thống nhất, thì chúng ta có thể chuyển hóa các quy tắc đó thành thuật toán để máy tính tự sinh mã. Máy tính không cần phải thông minh, nó chỉ cần thực hiện chính xác các quy tắc đã được định nghĩa sẵn.
Công cụ tôi xây dựng sử dụng ngôn ngữ C# để đọc cấu trúc cơ sở dữ liệu qua Reflection, rồi truyền thông tin đó vào các file template Handlebars.js để xuất ra mã nguồn.
Ví dụ, đây là template dùng để tạo ra lớp kiểm tra tính hợp lệ của dữ liệu đầu vào (Validator):
public class Create{{EntityName}}Validator : AbstractValidator<Create{{EntityName}}Request>
{
public Create{{EntityName}}Validator()
{
{{#each Properties}}
{{#if IsRequired}}
RuleFor(x => x.{{Name}}).NotEmpty().WithMessage("{{Name}} không được để trống");
{{/if}}
{{#if MaxLength}}
RuleFor(x => x.{{Name}}).MaximumLength({{MaxLength}}).WithMessage("{{Name}} không được quá {{MaxLength}} ký tự");
{{/if}}
{{/each}}
}
}
Khi công cụ chạy trên bảng Product trong cơ sở dữ liệu có thuộc tính Name (bắt buộc, dài tối đa 150 ký tự), nó tự động xuất ra file vật lý:
public class CreateProductValidator : AbstractValidator<CreateProductRequest>
{
public CreateProductValidator()
{
RuleFor(x => x.Name).NotEmpty().WithMessage("Name không được để trống");
RuleFor(x => x.Name).MaximumLength(150).WithMessage("Name không được quá 150 ký tự");
}
}
Bằng cách xây dựng các template tương tự cho tất cả các tầng kiến trúc theo mô hình Onion và Domain-Driven Design, công cụ có thể sinh ra toàn bộ mã nguồn của một tính năng chỉ trong chưa đầy một giây.
Đột phá cảnh giới nhờ bóc tách quy luật
Điều cốt lõi giúp công cụ sinh mã hoạt động hiệu quả không nằm ở công nghệ C# hay thư viện Handlebars.js. Nó nằm ở việc chúng ta có thể quy tắc hóa toàn bộ quy trình viết code của mình hay không.
Để viết được những file template Handlebars chính xác, tôi đã phải ngồi lại phân tích rất kỹ các quyết định viết code hàng ngày của mình. Tôi nhận ra mọi dòng code mình viết ra đều có một lý do logic đằng sau, và hầu hết các lý do đó đều có thể chuyển hóa thành các điều kiện lập trình.
Ví dụ, làm sao tôi quyết định khi nào cần hiển thị một ô chọn (dropdown) trên giao diện người dùng? Quy tắc rất đơn giản: nếu một trường trong bảng là khóa ngoại liên kết đến một bảng khác, điều đó có nghĩa là dữ liệu nhập vào phải thuộc danh sách các thực thể đã tồn tại. Do đó, trên giao diện UI, trường này phải được hiển thị dưới dạng một ô chọn lấy dữ liệu từ API của thực thể liên kết kia.
Khi tôi hệ thống hóa được tất cả các quy tắc này thành một bộ logic chặt chẽ, máy tính chỉ việc thực thi chúng một cách máy móc nhưng mang lại độ chính xác tuyệt đối.
Khoảnh khắc tôi chạy công cụ lần đầu tiên trên một database thực nghiệm rồi nhìn thấy hàng trăm file mã nguồn được sinh ra trong thư mục dự án, tất cả đều biên dịch thành công mà không có một lỗi cú pháp nào, tôi đã thực sự khai ngộ. Tôi nhận ra rằng việc cắm đầu gõ phím nhanh thực ra chỉ là phần nổi của tảng băng trôi.
Sự tương đồng về bản chất với AI
Trong thời điểm hiện tại, khi các công cụ hỗ trợ lập trình bằng trí tuệ nhân tạo như ChatGPT hay GitHub Copilot đang trở thành vật bất ly thân của giới lập trình, tôi nhận ra bản chất của AI coding và công cụ sinh mã bằng template tôi từng viết có rất nhiều điểm tương đồng.
Cả hai phương pháp đều cố gắng giải quyết một bài toán duy nhất: biến đổi thông tin từ dạng này (mô tả yêu cầu bằng ngôn ngữ tự nhiên, thiết kế database) sang dạng khác (mã nguồn chạy được) dựa trên các quy ước sẵn có.
Điểm khác biệt nằm ở cách thức chuyển hóa.
Công cụ sinh mã truyền thống dựa trên công thức: Quy tắc cứng + Template mẫu + Metadata. Phương pháp này yêu cầu sự chính xác tuyệt đối ngay từ đầu. Nếu bạn thiết kế database cẩu thả, công cụ sẽ sinh ra code lỗi hoặc không chạy được. Tuy nhiên, ưu điểm của nó là sự ổn định tuyệt đối và khả năng kiểm soát hoàn toàn.
Trong khi đó, AI Code Generation hoạt động theo công thức: Ngữ cảnh dự án + Prompt miêu tả + Mô hình xác suất. AI không cần các template được viết sẵn một cách cứng nhắc. Nó tự học cấu trúc code từ kho dữ liệu khổng lồ của nó và cố gắng dự đoán xem dòng code tiếp theo nên là gì để phù hợp nhất với ngữ cảnh hiện tại của bạn.
Nhưng dù sử dụng công cụ sinh mã bằng template hay AI, sự thành bại vẫn phụ thuộc vào một yếu tố cốt lõi: khả năng định nghĩa quy tắc của người sử dụng.
Nếu bạn không thể diễn đạt một cách rõ ràng và logic cấu trúc hệ thống của mình, nếu bạn không hiểu rõ luồng dữ liệu đi từ đâu đến đâu và cần được kiểm tra những gì, bạn sẽ không thể viết ra một template tốt, và bạn cũng không thể viết ra một câu prompt đủ chi tiết để AI hiểu đúng ý.
Viết code ít đi để suy nghĩ nhiều hơn
Hành trình tự xây dựng công cụ sinh mã cho đến việc quan sát sự phát triển của các công cụ lập trình tự động bằng AI đã thay đổi hoàn toàn tư duy của tôi về nghề lập trình.
Trước đây, tôi từng đo lường năng lực của một lập trình viên bằng tốc độ gõ phím, số lượng dòng code họ có thể viết ra mỗi ngày, hoặc khả năng nhớ cú pháp phức tạp của ngôn ngữ. Bây giờ, tôi nhận thấy những chỉ số đó đã trở nên lỗi thời.
Khi các công cụ tự động có thể viết hàng nghìn dòng code trong vài giây với chất lượng cú pháp hoàn hảo, việc cố gắng cạnh tranh với máy tính về tốc độ thực thi là một cuộc đua không cân sức và vô nghĩa.
Viết code thực chất chỉ là công đoạn thực thi cuối cùng của quá trình giải quyết bài toán. Giá trị cốt lõi của một kỹ sư phần mềm nằm ở quá trình suy nghĩ trước khi đặt tay lên bàn phím.
Đó là khả năng ngồi lắng nghe để thấu hiểu vấn đề thực tế của người dùng, phân tích và bóc tách những yêu cầu nghiệp vụ mơ hồ thành những ràng buộc kỹ thuật cụ thể. Đó là việc thiết kế một mô hình dữ liệu đủ linh hoạt để đáp ứng sự thay đổi của doanh nghiệp trong vài năm tới, nhưng cũng đủ đơn giản để hệ thống không bị quá tải.
Nếu thiết kế hệ thống sai ngay từ đầu, các công cụ sinh mã tự động hay AI chỉ giúp chúng ta tạo ra một hệ thống lỗi với tốc độ nhanh hơn và quy mô lớn hơn mà thôi.
Khi máy móc đã làm tốt việc thực thi các cấu trúc lặp đi lặp lại, lập trình viên sẽ được giải phóng khỏi những công việc mang tính thủ công. Chúng ta có nhiều thời gian và không gian tinh thần hơn để tập trung vào những phần việc thực sự cần đến tư duy sáng tạo và khả năng giải quyết vấn đề của con người.
Chúng ta tự động hóa những gì có quy luật, để dành trọn vẹn trí tuệ của mình cho những bài toán chưa có quy luật.
Nếu bạn dành 80% thời gian gõ code lặp đi lặp lại, bạn chỉ có 20% để suy nghĩ thực tế. Còn nếu máy viết code, tỷ lệ đó sẽ đảo chiều. Câu hỏi là: khi bạn có nhiều thời gian suy nghĩ hơn, bạn sẽ tạo ra cái gì?